![]() This
article has images that may be considered risque, ecchi, or NSFW.
This
article has images that may be considered risque, ecchi, or NSFW.
Towards the end of 2022 there was a sudden AI boom with many new tools being introduced. Among these were LLMs - like the famous ChatGPT - and image generation programs - like Midjourney and Stable Diffusion - which I decided to try for myself.
Since stable diffusion is open source, there exist many different forks and variants. Most of these are optimised for certain hardware. Since I was quite inexperienced I wanted any help I searched for online to be as applicable as possible. Hence, I decided to go for the main branch, AUTOMATIC1111’s stable-diffusion-webui.
I wasn’t sure if I would be able to generate high quality images since I only had a 1650 SUPER with 4GB of VRAM. VRAM is very important for AI, my understanding was that a greater amount of VRAM would lead to better results.
I followed this tutorial and started.
![]() 2023-05-25
2023-05-25
Setting up stable diffusion
https://github.com/AUTOMATIC1111/stable-diffusion-webui
Now that I had settled on the fork, I have to actually install it. First, I created a folder in the root of my C: drive.

Next, I opened command prompt in this folder, and called “git clone” to copy all the files. Most of the code for stable diffusion is written in Python, which means there is no need to compile it as it’s an interpreted language.
Now I must start the program. This is quite simple; I just need to launch the file “webui-user.bat”. This will create a local website that I can access in a browser, which serves as the access point for stable diffusion.
The stable diffusion web interface.
Now I need to get a model. Stable diffusion pulls its data from models and does some complicated mathematics (basically black magic) with the prompt that you provide to create an image. I decided I wanted to create anime images as I don’t have to achieve photo-realism, which would be very difficult on my limited hardware.
After researching some options I decided to use “Anything v5”, as it seemed to produce high-quality images in a variety of scenarios. I downloaded the model. (Which was quite large - 2 Gigabytes!)

I placed it in the folder “models/stable-diffusion”, then loaded the model in the interface. I noticed that loading the model took some time, over 1 minute. During this time my computer was experiencing severe performance issues - even my mouse cursor was struggling to move. This is most likely because I had created the installation on a HDD. After it was done I decided to generate my first image with the simple prompt “woman”, and the negative prompt “man”.
The beginnings

woman
Negative prompt: man
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2797208585, Size: 64x64,
Model hash: 7f96a1a9ca, Model: AnythingV5_v5PrtRE, Version: v1.2.1
Quite a disappointing result. The resulting image was tiny and a mess of colours. I realised that this was probably because I hadn’t changed any settings. I did some research, and after looking at https://stable-diffusion-art.com/samplers/ , I decided to use the sampler “DPM++ 2M Karras”. Currently I was using Euler a, which is an “ancestral” sampler, pretty slow, and unoptimised.
I also increased the resolution from 64x64 to 144x144. I decided to increase the resolution in small increments because I wasn’t sure what image size my computer would be able to handle. I also increased the number of steps and modified the seed and CFG scale.

woman
Negative prompt: man
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 15, Seed: -123, Size:
144x144, Model hash: 7f96a1a9ca, Model: AnythingV5_v5PrtRE, Version: v1.2.1
Still pretty bad, but at least it’s vaguely woman shaped. You can see legs, hair, bust and a dress, though it’s obviously quite disproportionate, even for anime, and the face is not visible.
With a new attempt, I bumped the image resolution all the way to 512x512, and gave it a new prompt, “woman at work”. I also decided to switch to using the model “Anything v4.5” as it actually seemed to be a bit better in comparison videos that I looked at on YouTube, despite being an older version.

woman at work
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2447014726, Size: 512x512,
Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
Now that’s a lot better. You can clearly see a woman sitting at a desk. However, the image lacks detail, and the composition is poor. The art style also is not exactly, it looks more like a Korean webtoon. I decided to try improving the prompt.

anime girl drinking starbucks over a sunset
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 1887137848, Size: 512x512,
Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
This is the first half-decent image I ever generated. You can see a sunset, the girl looks somewhat normal, and the composition is fine. Of course, the hands of the girl are an absolute mess, but that’s pretty difficult to fix, even the best ai-generated images struggle with hands.
It was at this point I discovered that putting -1 in the seed box generates the image with a random seed. I tried using the same prompt, but with a couple more seeds.
Some other generations, using other random seeds.




All images are also pretty good, however in one the girl has two cups, and in another she's pushing the straw into her chin, and looks like she's smoking a cigarette. Also, the quality of the image could still be better, these still look like amateur drawings. To try and increase the quality of the image, I expanded the prompt and increased the step count.

black background, jotaro in front, jotaro posing, jotaro pointing finger at
camera, star platinum stand behind, star platinum mouth open, star platinum
about to punch, particles coming out, pink, blue, purple
Steps: 60, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: -69420, Size:
512x512, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
The image still isn’t as good as I was expecting. It doesn’t seem to be very good at drawing men, which is expected, and Jotaro’s stand “Star Platinum” isn’t visible in the image.

joe biden in anime style
Steps: 60, Sampler: DPM++ 2M Karras, CFG scale: 22.5, Seed: -774924, Size:
512x512, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
I tried some other funny stuff too.
I wanted to see how much of a difference the step cound was making, so I generated two images, one with step count 30, and one with step count 70.


genshin impact
Steps: 70, 30, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 2451175280,
Size: 512x512, Model hash: fbcf965a62, Model: anything-v4.5, Version:
v1.2.1
The image is an absolute mess. It looks like it’s supposed to be “Ganyu” from Genshin Impact, but it’s terrible. Furthermore, as we can see, while the left image has a much higher step count, it’s not that much better. The step count isn’t making a big difference on the image.


beautful anime girl at summer
Negative prompt: bland background
Steps: 40, 150, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 2, Size:
512x512, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
Here’s another comparison. The image on the left has a step count of 40, while the one on the right has a step count of 150, which is the maximum. You could argue that the lower step count is actually better. I decided to stick to a lower step count from this point. At the back of my mind, I noticed that the images were kind of washed out, but I didn’t pay much attention.

beautiful anime girl with glowing rainbow hair
Negative prompt: bland background
Steps: 150, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 3067320398, Size:
512x512, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
This image has a step count of 150 and looks quite colourful and nice. I decided to start looking at improving the prompt. After doing some research, I realised that since the images were trained on websites like Danbooru and Gelbooru, in my prompt I should use the kinds of tags that I would expect on the website. I also copy-pasted a massive negative prompt that I found on reddit.

beautiful anime girl, glowing rainbow hair, evening time, dinner, rooftop,
sunset
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, bokeh, (((long neck))), ((flat
chested)), ((((visible hand)))), ((((ugly)))), (((duplicate))), ((morbid)),
((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn
hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)),
blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned
face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy),
gross proportions, (malformed limbs), ((missing arms)), ((missing legs)),
(((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too
many fingers), (((long neck))) red eyes, multiple subjects, extra heads,
bland background
Steps: 40, Sampler: Euler a, CFG scale: 16, Seed: 912897312, Size: 512x512,
Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1
This looks quite good. It still doesn’t look outstanding, but most oddities have been cleared out, and the general quality of the image is substantially better. The massive negative prompt is helping quite a lot.


Some other generations, using the massive negative prompt.
Now I wanted to try increasing the quality of the image again. I read online that not even the most powerful GPUs are able to generate at resolutions like 4k. Instead, they generate at a low resolution, then upscale. The webui has an upscaling tool built in.
I used the Anime6B upscaler, as it’s intended for anime.


The image is larger, but the quality is not better. The image still feels soft. I think this is because the starting image is so small there’s not much that the upscaler can do about it.
Next, I tried to increase the resolution, but every time I tried going past 512x512, I got a “CUDA out of memory” error.
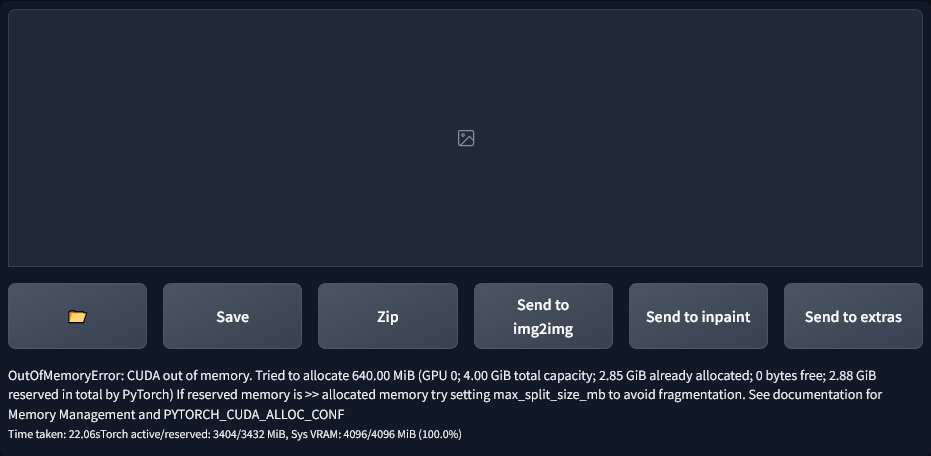
It seems that I’d landed on my hardware’s limit exactly, by chance. I decided to instead try generating some other things, like profile pictures. However, when I tried, I got the out of memory error again, despite me having gone down to 512x512. I lowered it a bit to 448x448, and it started working again. I can only assume that this is due to some memory leak. After looking online the only solution seemed to be to restart the program, but I was hesitant to because of the long loading times. I decided to just continue with my generations.




There were some oddities too:

At this point, I decided that I was done for the day.
![]() 2023-05-26
2023-05-26
experimentation
I tried generating some landscapes, by adding prompt detail about the background.

beautiful anime girl, in public, shops behind, people behind, sunny day
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, bokeh, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers,
mutated hands, ((poorly drawn hands)), ((poorly drawn face)),
(((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad
proportions))), ((extra limbs)), cloned face, (((disfigured))), out of
frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed
limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra
legs))), mutated hands, (fused fingers), (too many fingers), (((long
neck))) multiple subjects, extra heads, (human skin)
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 15, Seed: 1465219343, Size:
456x456, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.2.1



![]() 2023-05-29
2023-05-29
Other models
To take a break from generating anime images, I used a different model called “v1-5-pruned-emaonly” which is sort of “included” with the program. It’s trained on real photos.

cute anime girl
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 16, Seed: 2604315486, Size:
448x448, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Version: v1.3.0
Obviously, this model is pretty bad at generating anime images. First I decided to try making some plants.

fresh plant budding
Negative prompt: sad image
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 16, Seed: 1954333465, Size:
448x448, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Version: v1.3.0

fresh plant budding from the brown earth
Negative prompt: sad image
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 16, Seed: 1442190748, Size:
448x448, Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Version: v1.3.0
It’s not great. It’s pretty clearly AI-generated, and the images are still pretty small. I didn’t know how other people were making 4k images. I tried using the massive negative prompt again.


nice landscape
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3303073438, Size: 448x448,
Model hash: cc6cb27103, Model: v1-5-pruned-emaonly, Version: v1.3.0
I’m very happy with the first image, it actually looks like a real photo. It is a bit weird how the grass so close to the coast is cut like that, but I don’t think it’s unreasonable. The resolution again is quite poor, but I guess it’s believable if you said the image was taken in the early 2000s. However after some other cursed generations, I decided to stick with anime.


I generated some anime images with the general theme of a girl on a sunny day, wearing casual clothes.

cute anime girl, in public, sunny day
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 189439, Size:
448x448, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.3.0



Optimisation
I was able to get one image at 624x624 resolution, somehow.

This gave me the idea to look for ways to try and generate some higher resolution images. After some searching I found that by adding some parameters to “webui-user.bat”, I could sacrifice speed for lower VRAM usage, with --lowvram. I looked at several starting parameters, and ended up with this:
set COMMANDLINE_ARGS=--xformers --api --no-half-vae --lowvram --opt-split-attention --always-batch-cond-uncond --precision autocast --no-half
The main argument to look out for is –-lowvram. When I tried this, the image generation was much slower, nearly 10x slower, but it was worth it as I was able to generate images with a size of 768x768.

beautiful girl, in public, sunny day, casual clothing, cute girl, white
frilly clothing, summer hat, bag, windy
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 15.5, Seed: 753526979, Size:
768x768, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.3.0
Increasing the resolution seems to massively improve the quality. This image is very good, probably my best yet. With this high-resolution image, I tried using the upscaler again.

The quality of this image is great. I’m super happy with it.
I also tried a different model, called majicmix, which is supposed to be trained on Korean webtoons, but I just got images of east Asian people.

beautiful girl, sunny day, in public, casual clothing
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1066145363, Size:
768x768, Model hash: 33c9f6dfcb, Model: majicmixRealistic_v5, Version:
v1.3.0
Finally, I generated an image with a non-square aspect ratio. I generated a landscape image. Using an online tool I calculated that the biggest image I was able to generate was about 1MP, so I scaled the width and height accordingly.

anime girl, in public, sunny day
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 15.5, Seed: 1411489888,
Size: 853x480, Model hash: fbcf965a62, Model: anything-v4.5, Version:
v1.3.0
![]() 2023-05-30
2023-05-30
More experimentation
Now that I was able to generate much larger images, with a quality that I was happy with, I started experimenting. First, I re-generated the image of the anime girl with rainbow hair that I made earlier.

beautiful girl, ((glowing hair)), ((rainbow colored hair)), sunset,
rooftop, smiling, casual clothing
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads,
glasses, rainbow in background
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 18, Seed: 1717004739, Size:
768x768, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.3.0
I did try to use the same seed, but since the resolution was different, the resulting image was completely different.


I decided to incorporate some LLMs into this. I asked both Bing (GPT-4) and Bard (PaLM) to create a prompt for an anime girl. First was Bard, then Bing.

girl with long, flowing hair in pastel colors, standing in a field of
flowers, with particles of light and color swirling around her, soft pastel
gradient background, with a warm sun shining down, girl smiling and looking
at the viewer, peaceful expression on her face, girl's hair should be long
and flowing, with a slight wave to it, mix of pastel colors, such as pink,
blue, and green, girl should be wearing a light, flowing dress in a pastel
color, dress should be decorated with flowers and other details, particles
of light and color should be swirling around the girl in a gentle vortex,
variety of flowers, including roses, lilies, and tulips, gradient should
start with a light blue at the top and fade to a light pink at the bottom,
The sun should be shining down from the top left corner of the image. It
should be a warm, golden color.
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads,
glasses, rainbow in background
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 18, Seed: 1032190, Size:
768x768, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.3.0

A young anime girl with long pink hair and blue eyes. She is wearing a
white dress with frills and ribbons, and has a pair of angel wings on her
back. She is smiling and holding a bouquet of flowers in her hands. She is
standing in front of a cherry blossom tree in full bloom. The background is
a soft pastel sky with fluffy clouds. rounded art style, anime style,
cloverworks, onimai style
Negative prompt: long neck, out of frame, extra fingers, mutated hands,
monochrome, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, glitchy, (((long neck))), ((((ugly)))),
(((duplicate))), ((morbid)), ((mutilated)), extra fingers, mutated hands,
((poorly drawn hands)), ((poorly drawn face)), (((mutation))),
(((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))),
((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra
limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing
arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated
hands, (fused fingers), (too many fingers), (((long neck))), extra heads,
glasses, rainbow in background
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 18, Seed: 429303161, Size:
768x768, Model hash: fbcf965a62, Model: anything-v4.5, Version: v1.3.0
Bard made the anime girl with green hair, and Bing made the anime girl with pink hair. I think that Bing made the overall better image, even though I did personally add some stuff to it’s prompt.
LoRAs and Embeddings
At this point I was browsing https://civitai.com and www.reddit.com/r/stablediffusion regularly. On reddit, I saw a post showcasing the “add detail LoRA”. It looked pretty interesting so I tried it. After some looking, I found out that LoRAs can attach to any model, and can be used to fine-tune further for specific characters or effects. The add detail LoRA simply adds more detail to any image, which sounds promising.

Reducing detail towards the bottom, from the add detail LoRA.
The LoRA was quite small, only a couple of megabytes. I put it in the models/lora folder.

To enable it, you have to type a special syntax in the prompt box: “<lora:add_detail:1>”. The number can be adjusted to add the amount of detail that you want. I generated an image to test.


<lora:add_detail:1>
There was certainly more detail, but it didn’t exactly look better. It added lines in the hair, clouds in the background and many creases on the clothes that made the image look not great. I decided to see what would happen if I cranked up the LoRA.

<lora:add_detail:3>
With this, the image just looks like an over sharpened mess. The LoRA can also be used to make images less detailed with a negative number.


<lora:add_detail:-1>
These experiments showed that a value of less than one, around 0.2 to 0.5, would improve the quality with no real drawbacks, which is perfect. Next, I looked into embeddings. Embeddings can be used to condense prompts, the main use being that I could condense my massive negative prompt. There were two useful embeddings that I found, EasyNegative and ng_deepnegative_v1_75t. I used both. I downloaded the files and put them in the embeddings folder.
Enabling embeddings is simple, just type EasyNegative and ng_deepnegative_v1_75t into the negative prompt box.
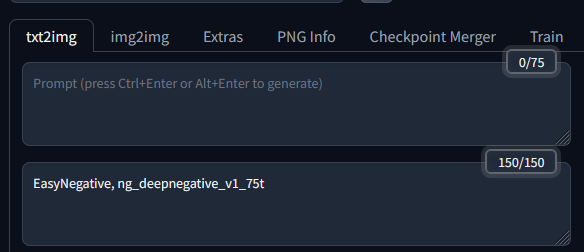
You can see that the token count is at 150, even though there’s only two phrases. The embeddings have many words inside of themselves. I decided to use the embeddings alongside the LoRA, and my original massive negative prompt, to make some high-quality battle themed anime images.


beautiful woman, warrior, commander, commanding army, intricate clothing,
detailed clothing, battle armour, working, standing, main focus, 1girl,
serious look on face, ((pointing at enemy)), top angle view, beautiful sky,
beautiful landscape, holding gun, large wings, feathered wings, sparkling
wings, white wings, battle goddess, medieval, high quality, absurdres, best
quality, high effort, <lora:add_detail:0.5>
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes,
skin blemishes, bad anatomy, red eyes, muscular, (worst quality, low
quality:1.3), makeup, mole, logo, watermark, text, glasses, mask, bad
anatomy, bad hands, fewer digits, missing arms, extra digit, muscular,
EasyNegative, ng_deepnegative_v1_75t, long neck, out of frame, extra
fingers, mutated hands, monochrome, ((poorly drawn hands)), ((poorly drawn
face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)),
(((bad proportions))), ((extra limbs)), cloned face, glitchy, (((long
neck))), ((((ugly)))), (((duplicate))), ((morbid)), ((mutilated)), extra
fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)),
(((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad
proportions))), ((extra limbs)), cloned face, (((disfigured))), out of
frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed
limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra
legs))), mutated hands, (fused fingers), (too many fingers), (((long
neck))), extra heads
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 11.5, Seed: 3125009659,
Size: 768x768, Model hash: fbcf965a62, Model: anything-v4.5, Lora hashes:
add_detail: 7c6bad76eb54, Version: v1.3.0
The quality is quite good. I’m pretty happy with the quality of my images now.
![]() 2023-05-31
2023-05-31
Wallpapers, VAE, img2img
I want to try something called img2img. So far I’ve been doing txt2img, which, as the name implies, allows you to convert a text input to an image. This will allow us to transform one image into another. This is the input image that I’ll use:

“Hitori Gotoh” from “Bocchi the Rock!”
You can put in a text input alongside the image. My goal was to change the image from the show’s art style to a more traditional anime style.

beautiful anime girl, pink hair, blue eyes, yellow and blue hair
decoration, street background, shop behind, japan, pink tracksuit, bocchi
the rock <lora:add_detail:1>
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 2.5, Seed: 1098764656, Size:
960x540, Model hash: fbcf965a62, Model: anything-v4.5, Denoising strength:
0.75, Lora hashes: add_detail: 7c6bad76eb54, Version: v1.3.0
Using a very low CFG scale, I got this image. Otherwise, I got mostly nonsense. It just seems to be a watercolour of the input image, and it’s not great. I tried a couple more times:


Until I got a decent image.

beautiful anime girl, pink hair, blue eyes, yellow and blue hair
decoration, street background, shop behind, modern japan, pink tracksuit,
bocchi the rock <lora:add_detail:1>
Negative prompt: watercolour, watercolor, oil painting, soft image, dull
colours, dull colors
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 13.5, Seed: 1965965995,
Size: 960x540, Model hash: fbcf965a62, Model: anything-v4.5, Denoising
strength: 0.75, Lora hashes: add_detail: 7c6bad76eb54, Version: v1.3.0
It just seems to take the general composition of the image and make a new one. It's fine, but not very useful. Next, I decided to try generating some more landscape images, as I’ve generated plenty of squares, and landscape is a much more pleasing aspect ratio.



At this point I came across something online called a VAE. It stands for variational autoencoder, and it’s supposed to go alongside models, to improve their quality by giving them better colours. I hadn’t installed any VAE. I looked for a VAE for everything v4.5, but I couldn’t find one. There was one for anything v3.0. Many people said that the VAE for everything v4.5 was baked in, but I noticed that this entire time my images were quite washed out. If you remember, I mentioned this towards the start of the article.
After some more looking, I came across this page: https://huggingface.co/ckpt/anything-v4.5-vae-swapped/tree/main which contained a model called everything v4.5 vae-swapped. I assumed this was the one with the baked VAE, so I downloaded it and tried it.

Identical prompt to the image above.
With immediate effect, the image I generated was much more vibrant and colourful. This entire time, I had been generating without a VAE, which is why my images were so washed out. I knew it felt like something was missing. I felt pretty sad that I had gone so long without knowing this, but in the end, it’s better to know it late than never.


A comparison of the same image, generated with and without the VAE.

A square image generated with the VAE.
At this point, I also decided to try another model, called Cetus-mix.




masterpiece, girl, outside, sunny day, white frilly dress, sunhat,
beautiful sky, landscape, beautiful landscape, wallpaper, desktop
wallpaper, best quality, saturated image, colorful, saturated colorful
image, bright colors, 4k, highres, insaneres, absurdres, high effort, high
quality, <lora:add_detail:0.5>
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, watermark, text, mask, EasyNegative,
ng_deepnegative_v1_75t, long neck, out of frame, ugly, extra limbs, gross
proportions, missing arms, missing legs, extra arms, extra legs, extra
fingers
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 4193523054, Size:
1288x724, Model hash: b42b09ff12, Model: cetusMix_v4, Lora hashes:
add_detail: 7c6bad76eb54, Version: v1.3.0
Cetus-mix let me generate beautiful images that are vibrant and colourful. They remind me of high-budget movies like Your Name and are totally wallpaper material. These images were beautiful, though it wasn’t really anything that I did, more that I just found a really good model. These are once again a significant improvement in quality.
Furthermore, with these high-resolution and high detail photos, I was able to create fantastic images using the upscaler. But I won’t be showing them here since they’ll slow down the website.
At this point I also started to cut down on my negative prompt, as I realised that a lot of it wasn’t really doing anything.
![]() 2023-06-02
2023-06-02
Controlnet
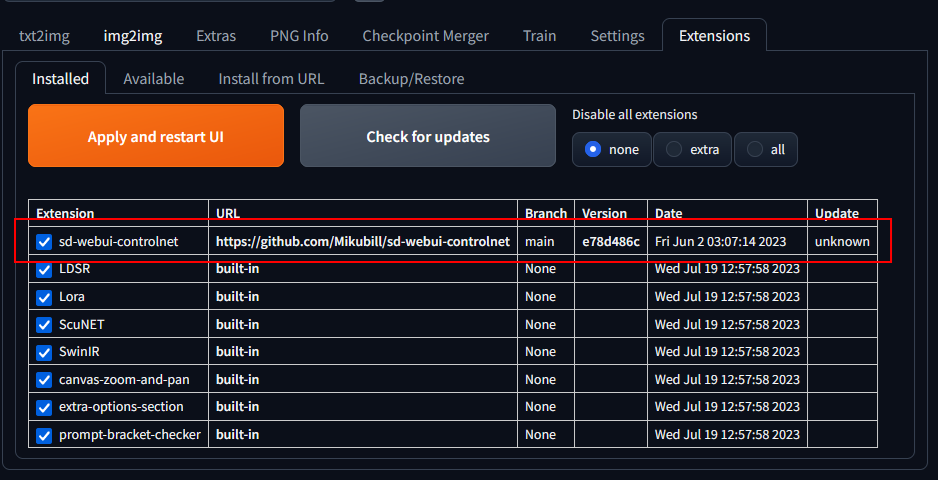
With the knowledge of the VAE, I feel like I’ve mastered basic image generation. I wanted to move onto something different called controlnet. Controlnet is a plugin that allows you to put in an image, like in img2img, and modify it. However, it allows you to exert much more control, which can be used to, for example, colourise line art. First, I downloaded controlnet and placed it in the extensions folder.

Next, I enabled it in the interface.
Now I need to choose a suitable image. After looking online, I decided upon this:

It’s line art and anime, so it’s perfect for filling in. I put the image into controlnet, and added a prompt.
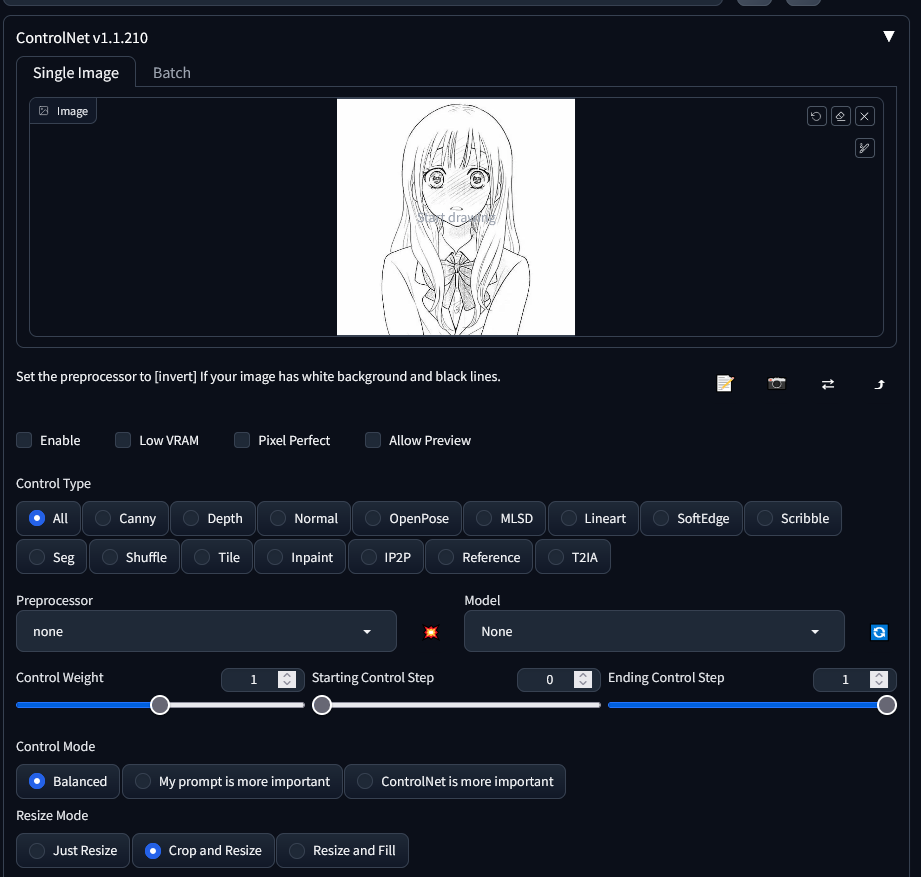
Now I need to choose a “preprocessor”. There are loads, all for different types of images. I eventually settled on scribble-xdog, as it produced a nearly one-to-one result.
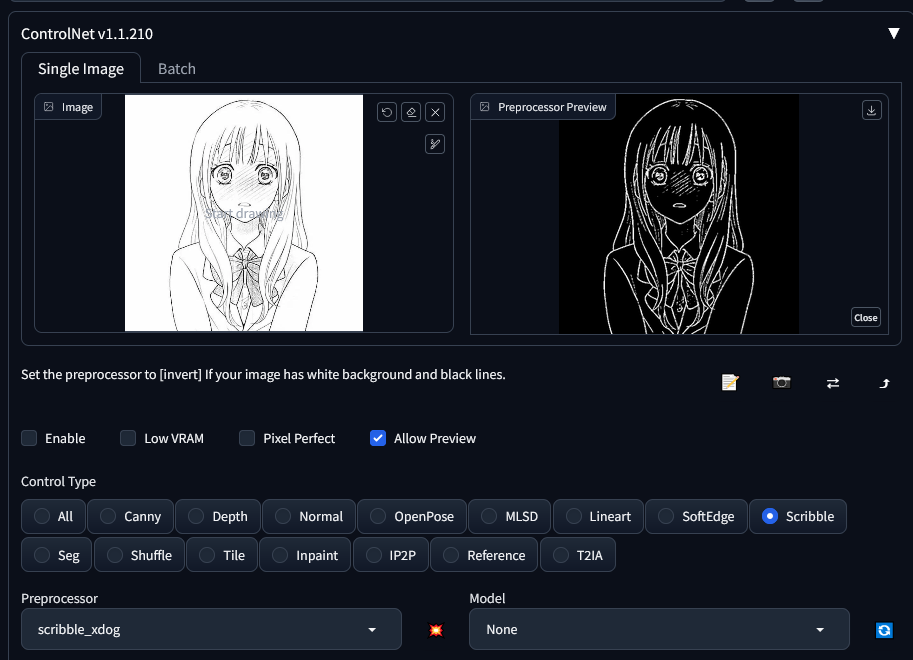
Without touching any of the other controls, I started generating images.

1girl, blushing, sunny, brown hair, school uniform, outside, school,
<lora:add_detail:1>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t
Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1691868254, Size:
768x768, Model hash: b0147c33be, Model: anything-v4.5-vae-swapped, Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.1-RC-6-gb6af0a38
It's a nice and cute image, but it looks nothing like the input. I generated a few more:




The images just look like if I had put in the prompt, without controlnet. I looked around and realised that I forgot to enable the extension. The check is pretty hidden.
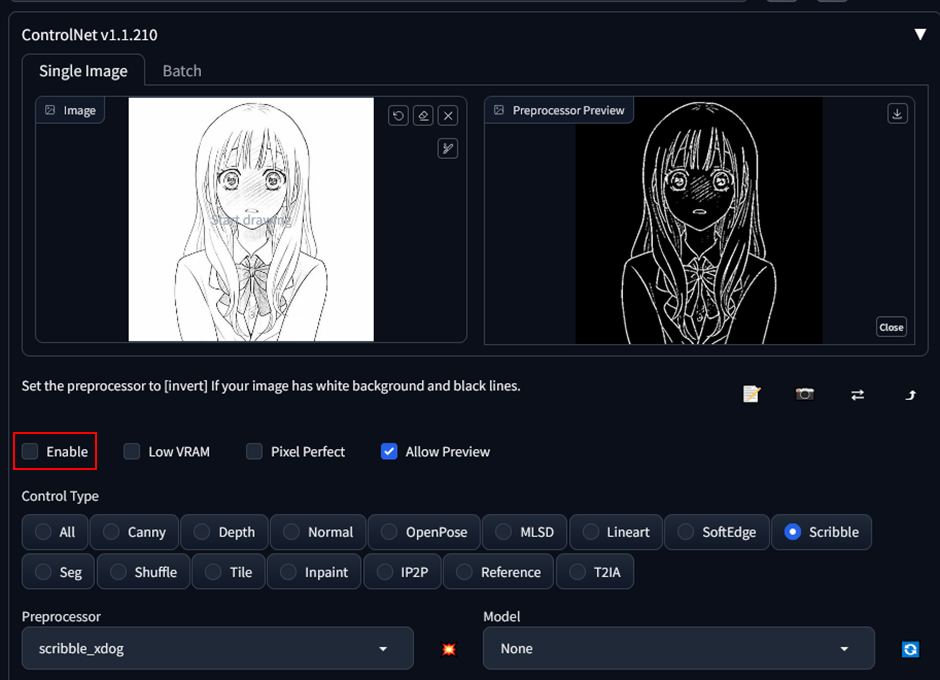
Generating one more time, I got this:

masterpiece, wallpaper, desktop wallpaper, 1girl, blushing, sunny, brown
hair, school uniform, school girl, outside, school,
<lora:add_detail:0.5>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t
Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 622530819, Size:
768x768, Model hash: b0147c33be, Model: anything-v4.5-vae-swapped,
ControlNet: "preprocessor: scribble_xdog, model: control_sd15_hed
[fef5e48e], weight: 1, starting/ending: (0, 1), resize mode: Just Resize,
pixel perfect: False, control mode: Balanced, preprocessor params: (768,
32, 64)", Lora hashes: "add_detail: 7c6bad76eb54", Version:
v1.3.1-RC-6-gb6af0a38
It’s very clearly the image that I put in, and it looks good. Controlnet is a powerful tool that could be used to colourise images easily and effectively. I ran one more time and reduced the weight of controlnet.

Weight: 0.5
The image is clearly still based on the input, but the program has added a background, and the head of the girl is tilted slightly. With a lower weight, controlnet could be used to turn a sketch into a full-fledged drawing. Next, I wanted to try drawing my own things in the image to see what would happen.

The left is supposed to be trees, and the right is supposed to be a wall, but unfortunately I’m terrible at drawing.

It’s understood that the things on the left are trees, but it didn’t understand that I meant to fully fill in the wall. Also, she looks like she’s in an apocalyptic landscape for some reason. This is fully a result of my awful drawing skills, though. I tried another sketch.


masterpiece, wallpaper, desktop wallpaper, 1girl, brown hair, pink dress,
cute dress, frilly dress, white background, <lora:add_detail:0.5>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t
Steps: 25, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 1435006750, Size:
740x1110, Model hash: b0147c33be, Model: anything-v4.5-vae-swapped,
ControlNet: "preprocessor: scribble_xdog, model: control_sd15_hed
[fef5e48e], weight: 1, starting/ending: (0, 1), resize mode: Crop and
Resize, pixel perfect: False, control mode: Balanced, preprocessor params:
(512, 35, 64)", Lora hashes: "add_detail: 7c6bad76eb54", Version:
v1.3.1-RC-6-gb6af0a38
This sketch isn’t actually a sketch, it’s also generated using stable diffusion, but I didn’t realise at the time. This one is a downgrade in my opinion, the colours of the dress are a poor choice, (since I forgot to change the prompt), the background is a bad colour, and something is missing about the face. It feels like the eyes have less detail. Stable diffusion also thinks that the lines at the top of the image are part of the dress, for some reason. I also personally love the variable thickness of the lines in the original line art.
![]() 2023-06-03
2023-06-03
I tried one more image with controlnet, this time more characters from “Bocchi the Rock!”.

Input image

pink hair, red hair, 2girls, hat, glasses, white background, fanart, line
art <lora:add_detail:0.5>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t, realistic,
background, detailed, masterpiece, brown hair, yellow hair
Steps: 20, Sampler: Euler a, CFG scale: 10, Seed: 2646773470, Size: 768x768,
Model hash: b42b09ff12, Model: cetusMix_v4, ControlNet: "preprocessor:
scribble_xdog, model: control_sd15_hed [fef5e48e], weight: 1,
starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect:
False, control mode: Balanced, preprocessor params: (512, 2, 64)", Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.1-RC-6-gb6af0a38
It's very difficult to tell stable diffusion which characters should have what colours. The left characters should have pink hair, and the right character should have red hair. Overall, it’s just a mess of colours and I’m not really sure why. I tried a couple more times.




left girl pink hair, right girl red hair, left girl hitori gotoh, right
girl tan suit, right girl tan jacket, left girl blue eyes, right girl navy
newsboy hat, right girl green eyes, right girl kita ikuyo, 2girls, bocchi
the rock, hat, glasses, white background, blank background, fanart, line
art <lora:add_detail:0.5>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t, realistic,
background, detailed, masterpiece, brown hair, yellow hair, mask, scarf,
green
Steps: 20, Sampler: Euler a, CFG scale: 10, Seed: 1314180621, Size: 768x768,
Model hash: b42b09ff12, Model: cetusMix_v4, ControlNet: "preprocessor:
scribble_xdog, model: control_sd15_hed [fef5e48e], weight: 1.5,
starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False,
control mode: Balanced, preprocessor params: (512, 2, 64)", Lora hashes:
"add_detail: 7c6bad76eb54", Version: v1.3.1-RC-6-gb6af0a38
Some of these do look a little better, but they’re still nothing close to what I was hoping for. I think that controlnet just can’t handle 2 characters at the same time. I decided to stop with controlnet for now.


Cute anime girls in cool and interesting poses
![]() 2023-06-04
2023-06-04
I did further experiments with the add detail LoRA at extreme values to see what would happen.












1girl, single subject, sailor uniform, sailor hat, long hair, blue hair,
water, boat, landscape, two hands, two legs, serious, storm, rain, dark
sky, standing <lora:add_detail:-10, -5, -3, -2, -1, 0, 0.5, 1, 2, 2.5,
5, 10>
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2),
lowres, normal quality, watermark, text, mask, EasyNegative,
ng_deepnegative_v1_75t, out of frame, ugly, extra limbs, gross proportions,
missing arms, missing legs, extra arms, extra legs, extra fingers, multiple subjects
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 2339599249, Size:
768x768, Model hash: b0147c33be, Model: anything-v4.5-vae-swapped, Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.1-RC-6-gb6af0a38
The highest levels of add detail produce some somewhat disturbing images, while the lowest produces a very interesting result. The characters are of a style called "chibi", with big heads and very small bodies. The program has understood that chibi is a distinct art style from anime, and has also placed it at a lower detail than normal anime.
![]() 2023-06-05
2023-06-05
more cetus mix
I made some more images with the Cetus mix model to see what it could make.










I also generated some anime guys since I’ve been generating literally only girls this entire time.




![]() 2023-06-06
2023-06-06
Realistic portraits
Now that I’m pretty thoroughly done with anime, I decided to move onto realistic portrait images. For this, I used the model “I can’t believe it’s not photography”. First, I copied a prompt from it’s page on civitai.com so I had something to start with.

close up of a european woman, ginger hair, winter forest, natural skin
texture, 24mm, 4k textures, soft cinematic light, RAW photo, photorealism,
photorealistic, intricate, elegant, highly detailed, sharp focus,
((((cinematic look)))), soothing tones, insane details, intricate details,
hyperdetailed, low contrast, soft cinematic light, dim colors, exposure
blend, hdr, faded <lora:add_detail:0.5>
Negative prompt: (deformed, distorted, disfigured:1.3), poorly drawn, bad
anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated
hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly,
disgusting, blurry, amputation
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1579114417, Size:
768x768, Model hash: 73f48afbdc, Model: icbinpICantBelieveIts_final, Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.2
Quite a lot better than I thought it would be, though the photoshop is a bit too much, and the woman looks a bit too perfect. I tried adding some words like “natural skin texture” but it was mostly the same, way too much makeup.

I removed some of the tags present in the original prompt to get a more realistic image.

It’s better than before but obviously still supermodel-level. At this point, I decided to add tags like “imperfect skin”, and even “meth addict”.




Quite a lot better than where I started. I also experimented with a change of background, and hair colour.




no lighting, natural light, european woman, red hair, copper hair,
ponytail, landscape in background, looking at camera, mountains, lake,
sunny, trees, forest, imperfect skin, 24mm, 35mm, 70mm, 4k, 8k, RAW photo,
intricate, elegant, low contrast, photo, portrait, picture, exposure blend,
hdr, full body shot, blemish, bad skin, pores, wrinkles, acne
<lora:add_detail:0>
Negative prompt: bokeh, blurred background, (deformed, distorted,
disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, flash, extra
limb, studio lighting, studio lights, missing limb, floating limbs,
disconnected limbs, mutation, mutated, disgusting, blurry, amputation,
photoshop, make-up, makeup, lores, low resolution, low quality, anime,
manga, comic, cartoon, thumbnail, realistic, artificial, plastic,
imitation, fake, rendering, painting, drawing, illustration, artwork,
sketch, airbrushed, cgi, doll hollywood, monotone, black and white
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 4.5, Seed: 1235743053, Size:
768x768, Model hash: 73f48afbdc, Model: icbinpICantBelieveIts_final, Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.2
I completely forgot about the add detail LoRA. It isn’t only for anime; it can be used for any type of image. First, I tried increasing the detail.


<lora:add_detail:1>
This looks fine. It’s added some more shadows, making it look like a sunny day. She also doesn’t appear to be wearing clothes, but luckily that’s out of frame. I’m not sure why the LoRA did that.


<lora:add_detail:2>
When stepping it up to strength 2, the results are not great. It’s adding shadows where it shouldn’t and ruining the image. I also tried some extreme values.


<lora:add_detail:2>
Pretty bad. Nothing much to say. Let’s move on. Next I want to try reducing the detail.




<lora:add_detail:-1>
Pretty perfect in my opinion. I’d say that you have a pretty solid chance of convincing someone that this is a real photo. The women look pretty, but reasonably so, and the shot is framed in an amateur way that looks like it’s taken on a phone. Let’s try some other values.


<lora:add_detail:-2>


<lora:add_detail:-5>
With -2, the hair loses detail, and with -5, it starts to look like a painting.
![]() 2023-06-07
2023-06-07
I tried a different hair colour and body type.


It looks good, But the image breaks down completely when hands are introduced.

I tried to make a person eating udon noodles, but it’s probably the worst choice I could have made.


Finally, I made a landscape and some weird pictures.

Nature's Enchantment <lora:add_detail:0.5>
Negative prompt: EasyNegative, ng_deepnegative_v1_75t
Steps: 10, Sampler: DPM++ 2M Karras, CFG scale: 4.5, Seed: 1473372436, Size:
768x768, Model hash: 73f48afbdc, Model: icbinpICantBelieveIts_final, Lora
hashes: "add_detail: 7c6bad76eb54", Version: v1.3.2


![]() 2023-06-09
2023-06-09
With the photography model, I generated some images of food.


It does look like food, but when you inspect it closer it doesn’t make sense. The obvious one is the rabbit head inside the rabbit soup. In the chicken, most of the meal looks to be chickpeas or something with a very small amount of rice, and there’s honey in the background. I also wanted to see if it could make scary images.


These look pretty unsettling to me.
![]() 2023-06-11
2023-06-11
Testing embeddings
So far I’ve been using both EasyNegative and DeepNegative in my prompts. I wanted to find out which of the two is better, or if both are better. I used the same seed and prompt, changing only the embeddings in the negative prompt. There is nothing else in the negative prompt.


None, EasyNegative


DeepNegative, Both

Both + Massive Negative Prompt
As you can see the negative prompt is pretty important. EasyNegative and DeepNegative are good, but it doens't come close to what the big negative prompt does. However, between EasyNegative and DeepNegative, I would say that EasyNegative is better. Using this information, I was able to create the following negative prompt:

Negative prompt: EasyNegative, (worst quality:2), (low quality:2), (normal quality:2), logo, watermark, ugly, monochrome, disfigured, morbid, mutation, deformed, out_of_frame, malformed
It comes close to the quality of the massive negative prompt at a fraction of the character count.
Conclusion
On just 4GB of VRAM, I was able to create some pretty stunning images. I learned a lot of things, like refining my negative prompt, using different models, using LoRAs, optimising for a higher resolution image, using controlnet and using VAEs. I think stable diffusion is a pretty powerful tool, and will become a useful tool in the future, specifically controlnet, which could be used to easily colour in line art and concepts, acting like a fill bucket on steroids.